
LOAD DATA LOCAL INFILE – BBDD `dogs`
Aquesta base de dades relacional, en MySQL, està construida a partir un dataset, que en part prové de dades públiques del FCI (Federació Cinològica Internacional) o Federació Internacional de races canines.

Veiem un cas concret sobre aquesta BBDD
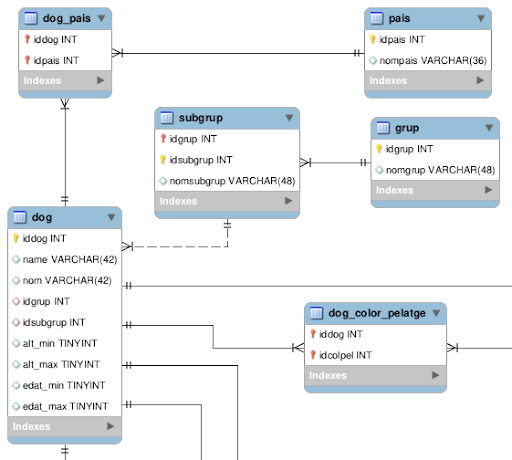
La taula `dog` representa la taula principal, amb les diferents races de gossos, els grups i subgrups principals i altres atributs concrets de cada raça.
La relació de la taula `dog` amb la taula pais, és N:M ja que algunes races poden ser originàries de diversos països i cada pais pot tenir com a origen més d’una raça de gossos. Així doncs, tindrem una taula `pais` amb la llista de països i una taula intermitja `dog_pais` relacionada amb `dog`i amb `pais`, amb clau primària, les PK de `dog` i de `pais`.
Cas 1: Importació de dades a la taula `dog`
Per importar les dades a la taula dog, podem crear una taula temporal i amb LOAD DATA.. inserir les dades que després transferirem a la taula finalista `dog`. En un altre moment, veurem quin ha estat el procés exacte per a obtenir cada atribut amb els seus valors.
Cas 2: Importació de dades a la taula `pais`
La taula pais està creada de la següent forma:
CREATE TABLE pais (
idpais INT AUTO_INCREMENT,
nompais VARCHAR(36) UNIQUE,
PRIMARY KEY (idpais)
) engine=innoDB;En aquest cas, la columna de dades de la taula `pais` conté dades atòmiques en la majoria de registres, però en alguns casos, les dades són multivaluades o multivalor, separades amb comes dins de la mateixa columna.
El problema en un cas com aquest, és que la quantitat de valors podria no ser fix i per tant ens podem trobar amb columnes d’un, dos o més valors.
Dintre de l’script que realitzem per importar les dades, crearem una taula temporal en base a la taula pais, però que recollirà les dades tal qual apareixen en el dataset de forma que després puguin ser tractades amb SQL per enviar-les a la taula finalista `pais`.
DROP TEMPORARY TABLE IF EXISTS temp_pais;
CREATE TEMPORARY TABLE IF NOT EXISTS temp_pais LIKE pais;
LOAD DATA LOCAL INFILE '/home/usuari/sql/dogs_breeds_columns.csv'
IGNORE INTO TABLE temp_pais
FIELDS TERMINATED BY '\t' ENCLOSED BY '"' ESCAPED BY '"' LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@dummy, @dummy, @dummy, @dummy, nompais) SET idpais = NULL;Com necessitarem una PK (primary key) abstracta per la taula pais, el seu id l’enviarem com NULL, donat que la PK no permet valors NULL i es autoincremental, anirà creant un id propi i seqüencial.
En el cas de nompais, conté una clàusula UNIQUE el que ens ajudarà a que no poguem tenir noms que ja hem inserit abans i que complementarem, per descartar errors, la clàusula IGNORE (com si fèssim un INSERT IGNORE…) però en el LOAD DATA..
Una vegada tenim en la taula temp_pais totes les dades provinents del dataset i sense repeticions, totes aquelles que no siguin atòmiques, les haurem de separar en registres independents.
Select * From temp_pais limit 5,10;
Per fer-ho farem ús del següent codi, però que encara no anirà a la taula `pais`, ja que l’enviament final ho farem de forma ordenada pel nom de cada pais respecte el seu id abstracte. Això no és necessari, és més una qüestió estètica.
DROP TEMPORARY TABLE IF EXISTS 2pais;
CREATE TEMPORARY TABLE IF NOT EXISTS 2pais LIKE pais;
-- Ara inserirem de forma unitaria
INSERT IGNORE INTO 2pais
SELECT NULL, RTRIM(LTRIM(SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ',', n), ',', -1))) AS Valor
FROM temp_pais
CROSS JOIN (
SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
) AS numbers
WHERE n <= 1 + LENGTH(nompais) - LENGTH(REPLACE(nompais, ',', ''))
AND nompais <> '';
-- Ara ja tindrem els insert ordenats alfabèticament amb la següent comanda
INSERT IGNORE INTO pais SELECT NULL, nompais FROM 2pais ORDER BY 2;
DROP TEMPORARY TABLE IF EXISTS temp_pais;
DROP TEMPORARY TABLE IF EXISTS 2pais;Què fa exactament el codi en negreta?
Abans de res fem un aclariment, i és que l´ús d’aquesta segona taula temporal 2pais, la podem ometre tranquilament, ja que aquí només l’hem creada a tall d’exemple. Si volem que l’INSERT IGNORE… vagi directament a la taula pais, només hem d’afegir l’ORDER BY 2 que tenim en negreta al segon INSERT, al final del primer. D’aquesta forma ens estalviem la taula 2pais i un insert addicional. La sentència final seria:
INSERT IGNORE INTO pais
SELECT NULL, RTRIM(LTRIM(SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ',', n), ',', -1))) AS Valor
FROM temp_pais
CROSS JOIN (
SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
) AS numbers
WHERE n <= 1 + LENGTH(nompais) - LENGTH(REPLACE(nompais, ',', ''))
AND nompais <> '' ORDER BY 2;
DROP TEMPORARY TABLE IF EXISTS temp_pais;El trossejarem per analitzar-lo per parts.
SELECT NULL, RTRIM(LTRIM(SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ‘,’, n), ‘,’, -1))) AS Valor FROM temp_pais;
El NULL que projectem, com hem comentat abans, farà que se li assigni un nou id què és autoincremental.
La resta de la subconsulta realitza diverses operacions de manipulació de cadenes per extreure la part desitjada de cada fila de la taula temp_pais.
Què passaria si féssim SELECT només ? On tenim la n, el substituirem per una posició.
(a)
SELECT idpais, RTRIM(LTRIM(SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ',', 1), ',', -1))) AS Valor FROM temp_pais limit 5,10;
SELECT idpais, RTRIM(LTRIM(SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ',', 2), ',', -1))) AS Valor FROM temp_pais limit 5,10;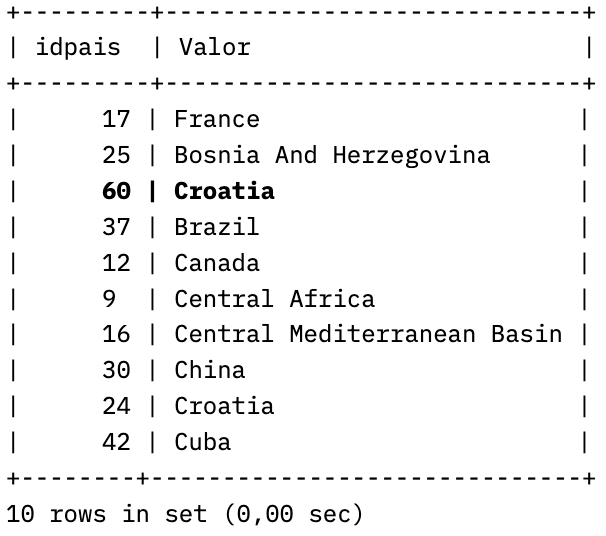
Podem veure com el registre amb idpais (60) que conté dos valors, en el primer cas torna el primer i en el segon select el segon, ja que hem substituit n per un valor numèric de posició. El problema és que no sabem quants podem tenir en cada registre.
Per altra banda, quan la sentència es converteixi en INSERT IGNORE … aquest ignore juntament amb la clàusula UNIQUE de l’atribut nompais (Valor en el select) farà que si la dada que enviem ja existeix, passi a la següent, en el nostre cas en quedarem amb Croatia, ja que Bosnia And Herzegovina, existia en el registre (25).
Vegem-ho pas a pas, anant des del centre de la sentència cap als extrems.
SUBSTRING_INDEX(nompais, ‘,’, n): Divideix la cadena nompais en parts separades per comes i selecciona la part fins a la posició n.
(b)
SELECT * FROM temp_pais WHERE idpais=60;
SELECT SUBSTRING_INDEX(nompais, ',', 1) AS nompais FROM temp_pais WHERE idpais=60;
SELECT SUBSTRING_INDEX(nompais, ',', 2) AS nompais FROM temp_pais WHERE idpais=60;
SELECT SUBSTRING_INDEX(nompais, ',', 3) AS nompais FROM temp_pais WHERE idpais=60;Un cop hem arribat al número de posicions (2 en l’exemple), qualsevol valor superior no pot mostrar més ocurrències. Per això hem d’establir un límit.
El següent SUBSTRING_INDEX agafarà el resultant anterior, retornant la darrera cadena.
SUBSTRING_INDEX(…, ‘,’, -1): Retorna l’última part de la cadena resultant, que és la part desitjada.
En aquest cas, el valor (…) serà la sentencia anterior i la posició o índex serà fixa (-1) que indica la darrera posició per la dreta.
(c)
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ',', 1), ',', -1) AS nompais
FROM temp_pais WHERE idpais=60;
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ',', 2), ',', -1) AS nompais
FROM temp_pais WHERE idpais=60;
Si ens hi fixem en les sortides, podem tenir espais no desitjats, després o abans de cada paraula, un cop es divideix, així que els eliminarem amb LTRIM (per l’esquerra) i RTRIM (per la dreta).
LTRIM(…) i RTRIM(…): Eliminen els espais en blanc a l’esquerra i a la dreta de la cadena resultant.
AS Valor: Assigna el resultat a una columna anomenada Valor.
El resultat, seria l’obtingut en l’apartat (a)
SELECT idpais, RTRIM(LTRIM(SUBSTRING_INDEX(SUBSTRING_INDEX(nompais, ',', n), ',', -1))) AS Valor FROM temp_pais limit 5,10;Com calculem n ?
A priori podem saber quin serà el número màxim d’ocurrències o d’elements diferents separats per ‘,’ que ens podem trobar.
(d)
Select MAX(length(nompais) - length(replace(nompais, ',', ''))+1) as elements From temp_pais;El que fem és contar la quantitat de caràcters de cada registre i restar els que quedarien si substituim l’element de cerca per no res ‘’, o en altres paraules com si l’eliminessim de la longitut de cerca original.
Amb aquesta opció podem determinar el màxim d’elements a tenir en compte en la següent part de la sentència.
En aquest cas i per simplificar i fer-ho extensible a totes les taules, hem agafat sempre el màxim número de valors, que serien 5.
Ara realitzarem sobre la sentència anterior [ apartat a) ] un CROSS JOIN múltiple, de forma que en ajudi a independitzar cada element trobat en un registre i que separarem amb diversos UNION.
(e)
CROSS JOIN (SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) AS numbersEs crea una taula temporal anomenada numbers que conté una columna n amb valors del 1 al 5.
CROSS JOIN: Realitza una combinació de totes les files de la taula temp_pais amb totes les files de la taula temporal numbers, generant un conjunt ampliat de dades.
Per últim farem servir en la condició WHERE, quelcom similar a l’indicat en l’apartat (d) però de forma que vagi tornant la possició de cada element separat per ‘,’ des de l’esquerra.
WHERE n <= 1 + LENGTH(nompais) - LENGTH(REPLACE(nompais, ',', '')) AND nompais <> ''Aquesta clàusula WHERE estableix les condicions per filtrar les files que es seleccionaran per a la transferència.
n <= 1 + LENGTH(nompais) - LENGTH(REPLACE(nompais, ',', ''))Garanteix que només es seleccionin fins a la darrera part de la cadena separada per comes. La part dreta d’aquesta condició calcula el nombre màxim de parts possibles en la cadena.
nompais <> ”
Assegurem que la cadena no estigui buida.
Per tant, de cara a veure n, la nostra consulta tornaria com a resultats:
SELECT *, RTRIM(LTRIM(SUBSTRING_INDEX
(SUBSTRING_INDEX(nompais, ',', n), ',', -1))) AS Valor
FROM temp_pais JOIN
(SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 ) AS numbers
WHERE n <= 1 + LENGTH(nompais) - LENGTH(REPLACE(nompais, ',', ''))
AND nompais <> '' LIMIT 5,10;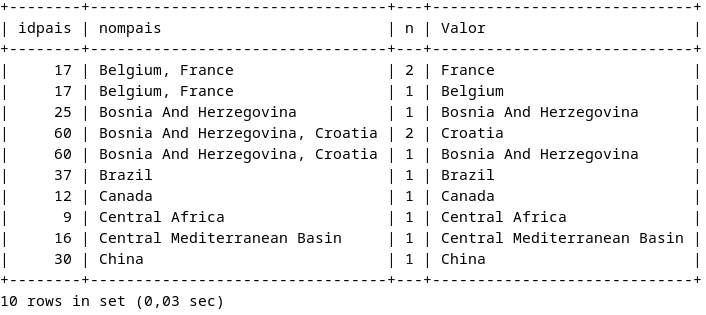
Com només ens interessa idpais i Valor, la sentència final seria:
-- Ara inserirem de forma unitària i ordenada
INSERT IGNORE INTO pais
SELECT NULL, RTRIM(LTRIM(SUBSTRING_INDEX
(SUBSTRING_INDEX(nompais, ',', n), ',', -1))) AS Valor
FROM temp_pais
CROSS JOIN (
SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
) AS numbers
WHERE n <= 1 + LENGTH(nompais) - LENGTH(REPLACE(nompais, ',', ''))
AND nompais <> '' ORDER BY 2;
DROP TEMPORARY TABLE IF EXISTS temp_pais;Cas 3: Importació de dades a la taula `dog_pais`
Ara, només ens quedaria omplir la taula dog_pais, que és la taula intermitja entre les taules `dog` i `pais`, on necessitarem els identificadors de cada taula, que formen la clau primaria de `dog_pais`.
De forma similar al que hem fet fins ara, el conjunt de sentències serien:
DROP TEMPORARY TABLE IF EXISTS tmp;
CREATE TEMPORARY TABLE IF NOT EXISTS tmp (
id INT,
atribut VARCHAR(80)
);
LOAD DATA LOCAL INFILE '/home/usuari/sql/dogs_breeds_columns.csv'
IGNORE INTO TABLE tmp
FIELDS TERMINATED BY '\t' ENCLOSED BY '"' ESCAPED BY '"' LINES TERMINATED BY '\n' IGNORE 1 LINES
(@id, @dummy, @dummy, @dummy, @atribut) SET id=@id, atribut=@atribut;
INSERT INTO dog_pais (iddog, idpais)
SELECT id,
( SELECT p.idpais FROM pais p WHERE p.nompais LIKE
RTRIM(LTRIM(SUBSTRING_INDEX(SUBSTRING_INDEX(atribut, ',', n), ',', -1))) ) AS Valor
FROM tmp
CROSS JOIN (
SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
) AS numbers
WHERE n <= 1 + LENGTH(atribut) - LENGTH(REPLACE(atribut, ',', ''))
AND atribut <> '';
DROP TEMPORARY TABLE IF EXISTS tmp;L’id que correspon a l’identificador de la raça de gos, és la que importem amb LOAD DATA, l’altre identificador idpais l’obtindrem d’una subconsulta aplicant el que hem vist anteriorment.