En un Sistema Gestor de Bases de Dades com MySQL, tenim algunes bases de dades que gestionen no només el comportament del servidor sinó també serveixen per a gestionar internament les bases de dades d’usuari. Per defecte, quan instal·lem MySQL server, ens trobarem les següents bases de dades del servidor:
SELECT schema_name From information_schema.schemata LIMIT 4;

D’aquestes BBDD ens fixarem en el diccionari de dades del servidor, que resideix en: information_schema
D’entre les seves taules, prop de vuitanta, les següents formaran part del diccionari.
catalogs: Informació del catàleg.
character_sets: Informació sobre els jocs de caràcters disponibles.
check_constraints: Informació sobre les restriccions de comprovació definides a les taules.
collations: Informació sobre les col·leccions per a cada joc de caràcters.
column_statistics: Estadístiques de l'histograma per als valors de les columnes. "Optimizer Statistics".
column_type_elements: Informació sobre els tipus utilitzats per les columnes.
columns: informació sobre les columnes a les taules.
dd_properties: taula que identifica les propietats del diccionari de dades, com la seva versió, que determina si el dd s'ha d'actualitzar.
events: Informació sobre els esdeveniments del programador d'esdeveniments.
foreign_keys, foreign_key_column_usage: Informació sobre claus foranes.
index_column_usage: Informació sobre les columnes utilitzades pels índexs.
index_partitions: Informació sobre les particions utilitzades pels índexs.
index_stats: S'utilitza per a emmagatzemar les estadístiques d'índex dinàmic generades quan s'executa la taula ANALYZE.
indexes: informació sobre els índexs de la taula.
innodb_ddl_log: emmagatzema els registres DDL per a operacions DDL segures.
parameter_type_elements: Informació sobre els paràmetres de procediments, funcions emmagatzemades, i els seus valors de retorn.
parameters: Informació sobre els procediments i funcions emmagatzemades.
resource_groups: Informació sobre els grups de recursos.
routines: informació sobre els procediments i funcions emmagatzemades.
schemata: Informació sobre schemata o database. En MySQL, un esquema és una base de dades.
st_spatial_reference_systems: Informació sobre els sistemes de referència espacial disponibles per a les dades espacials.
table_partition_values: Informació sobre els valors utilitzats per les particions de la taula.
table_partitions: Informació sobre les particions utilitzades per les taules.
table_stats: Informació sobre les estadístiques dinàmiques de la taula generades quan s'executa la taula ANALYZE.
tables: Informació sobre les taules a les bases de dades.
tablespace_files: Informació sobre els fitxers utilitzats pels espais de taula.
tablespaces: informació sobre els espais de taula actius.
triggers: Informació sobre triggers o disparadors.
view_routine_usage: Informació sobre les dependències entre les vistes i les funcions emmagatzemades utilitzades per elles.
view_table_usage: S'utilitza per a fer un seguiment de les dependències entre les vistes i les seves taules subjacents.Però què és un diccionari de dades, d’una base de dades d’usuari?
Bàsicament és un llistat de les taules (BASE TABLE) i vistes (SYSTEM VIEW) i la seva descripció o estructura (describe) que ens informa de les seves claus, índex, dominis, etc.. incloent els comentaris (COMMENT) que hem afegit al crear-les, en resum, les metadades de les taules. També podem acompanyar-les del seu esquema gràfic, que podem obtenir mitjançant enginyeria inversa, així com tot allò que pugui descriure a la base de dades en general i les seves taules i columnes en particular, la finalitat de cadascuna i fins i tot, aquells elements (procediments o store procedures, funcions, disparadors o triggers i events).
Una forma ràpida de crear un diccionari de dades, és amb una comanda que retorni les columnes i tipus de cada taula de la nostra base de dades.
SELECT t.table_name, t.table_comment, c.column_name, c.data_type, c.character_maximum_length, c.numeric_precision, c.is_nullable \
FROM information_schema.tables AS t JOIN information_schema.columns as c ON ( c.table_name = t.table_name ) \
WHERE t.table_schema = database() ORDER BY t.table_name, c.ordinal_position;A nivell individual, taula a taula, podem fer servir una sentència del tipus:
SELECT t.COLUMN_NAME, t.COLUMN_TYPE, t.COLUMN_DEFAULT, t.COLUMN_KEY, t.EXTRA, t.COLUMN_COMMENT FROM information_schema.COLUMNS t WHERE TABLE_SCHEMA = "insmvm" AND TABLE_NAME = "modul";
Una altra forma, seria utilitzant un procediment amb cursor que ens retorni aquests elements de forma ordenada per a cada taula i fins i tot les escrigui en un arxiu de sortida.
DROP PROCEDURE IF EXISTS p_diccionari;
Delimiter //
Create Procedure p_diccionari (IN nomdb VARCHAR(20))
COMMENT "Procediment per exportar les columnes de cada taula de la bbdd entrada per paràmetres
Per desar la sortida, abans de cridar el procediment
Crea un arxiu nou: [ '\\! touch /tmp/sortida.txt' ]
Executa: [ 'pager tee -a /tmp/sortida.txt' ]
Quan acabi el procediment:
Executa: [ 'nopager; notee;' ] "
Begin
DECLARE fi INT(1) DEFAULT 0;
Declare nomcol, defcol, extcol, nomtbl VARCHAR(20);
Declare keycol CHAR(3);
Declare tipcol, comcol VARCHAR(80);
DECLARE curstaula CURSOR FOR
Select TABLE_NAME FROM information_schema.TABLES WHERE TABLE_SCHEMA = nomdb;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET fi=1;
Select CONCAT ('Base de dades [ ', nomdb, ' ] Data: [ ', now(), ' ] ') AS 'Diccionari de dades ';
OPEN curstaula;
REPEAT
FETCH curstaula INTO nomtbl;
IF (fi = 0) THEN -- es manté funcionant el repeat
SELECT TABLE_NAME AS 'NOM TAULA', TABLE_COMMENT AS 'COMENTARI TAULA' FROM
information_schema.TABLES WHERE TABLE_SCHEMA = nomdb AND TABLE_NAME = nomtbl;
SELECT t.COLUMN_NAME AS 'Atribut', t.COLUMN_TYPE AS 'Tipus atribut', t.COLUMN_DEFAULT AS 'Per defecte', t.COLUMN_KEY AS 'Clau', t.EXTRA AS 'Extra', t.COLUMN_COMMENT AS 'Comentari' From information_schema.COLUMNS t WHERE TABLE_SCHEMA = nomdb AND TABLE_NAME = nomtbl;
END IF;
UNTIL fi END REPEAT;
CLOSE curstaula; -- tanquem el cursor
END //
nopager//
notee//
Delimiter ;
SELECT 'Per desar la sortida, abans de cridar el procediment ' AS 'ATENCIO !! ';
SELECT 'Executa: pager tee -a /tmp/sortida.txt' AS 'Crea un arxiu: \\! touch /tmp/sortida.txt';
SELECT 'Executa: nopager; notee; ' AS 'Quan acabi el procediment ';
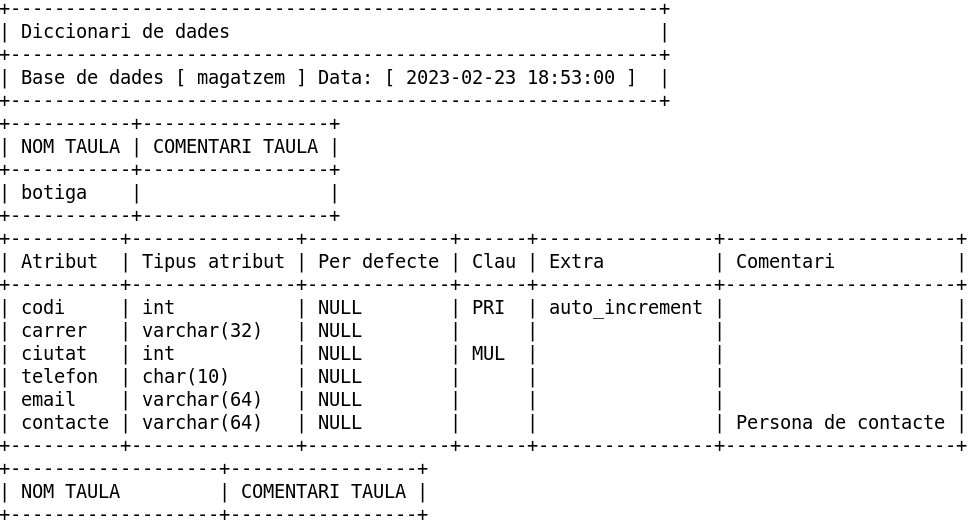
Nota: Quants més comentaris de taula o columna afegim, millor estarem documentant la nostra base de dades.
També tenim altres opcions per a obtenir de forma automàtica el nostre diccionari de dades, per exemple amb phpMyAdmin o MySQL-Workbench
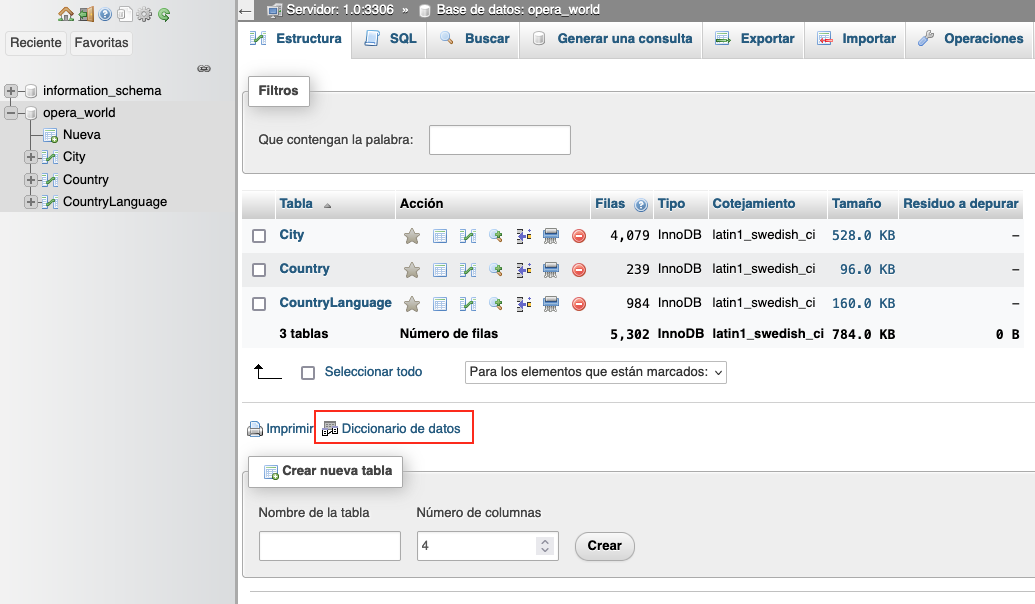
Si pel contrari, volem fer servir MySQL-Workbench, podem trobar diferents plugins, normalment escrits en python, que ens permetran fer una extracció en format .txt, .pdf o .html
Només obrir workbench, podem instal·lar el plugin (un cop descomprit l’arxiu xxdatadictxx.tar.gz) des del menú Scripting / Install Plugin/Module…
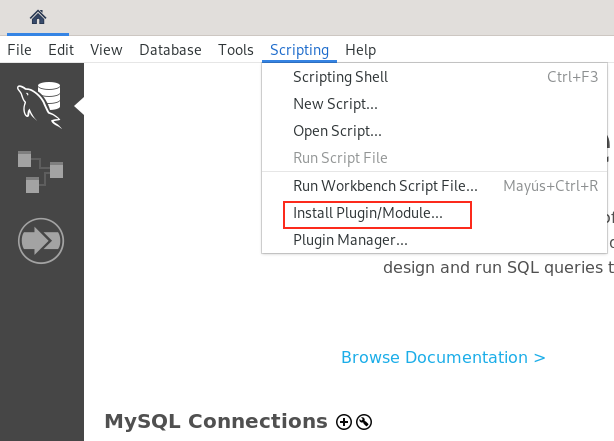
Haurem de reiniciar workbench i un cop entrem a la nostra BBDD haurem d’anar a la fitxa del model.
Simplement haurem de anar al menú Database / Reverse Engineer.. i situar-nos en la pestanya del model de la base de dades que hem carregat. Un cop allà, anirem al menú Tools / Catalog / Generate HTML Data Dictionary i li direm la ruta i el nom de l’arxiu de sortida, que tindrà en aquest cas, extensió .html
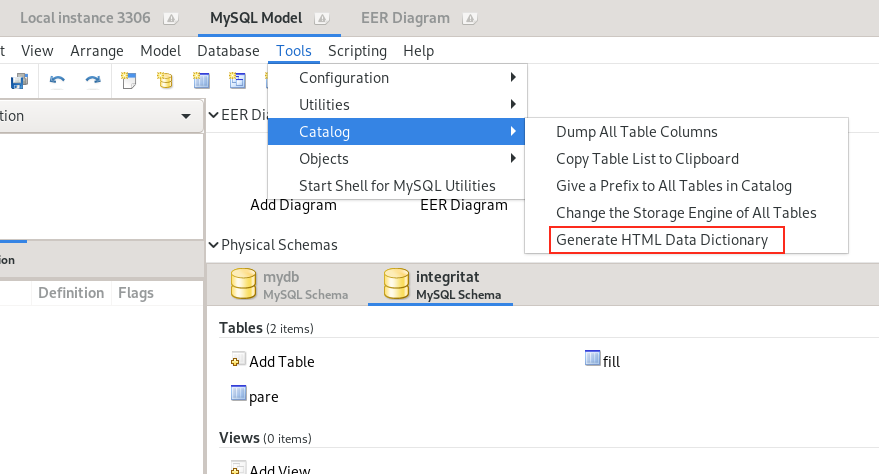
Exemple de base de dades ‘integritat’ que consta de dues taules que he fet servir en algún cas per explicar la integritat referencial
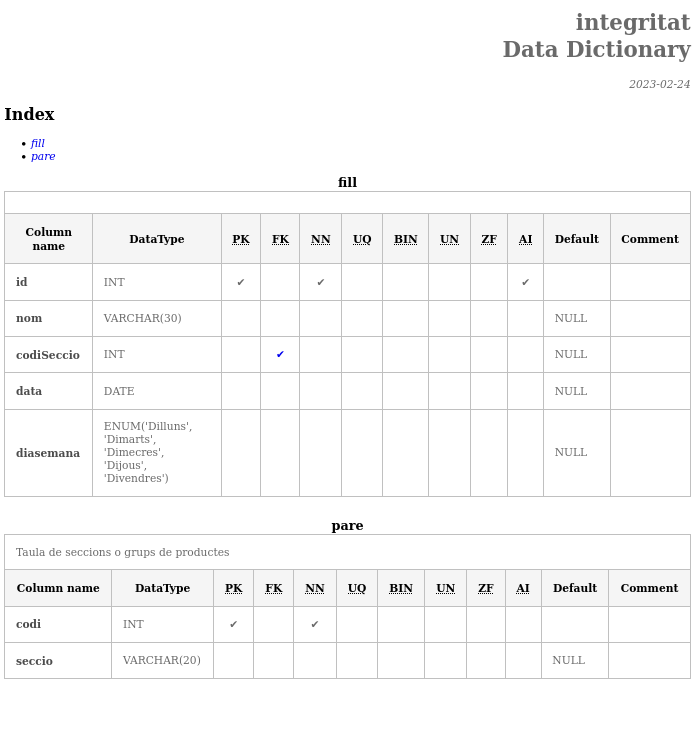
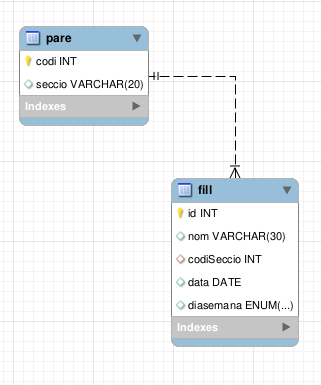
Un exemple real d’us, d’aquesta terminologia de diccionari de dades, la podeu trobar a l’hora de descarregar els datasets o conjunt de dades, que en obert ens ofereix Renfe a la seva web, després de la previsualització del .CSV o .XLS de dades, us trobeu amb el seu diccionari de dades, què el que ens ve a dir, és bàsicament, el nom i tipus de les columnes.